Re: retrieving class
Hi Clifton,
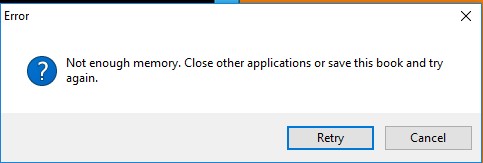
Thanks for your help. I did what you suggested but the problem is still there. I am loading 3 HTML docs and 2 TB DHTMLs. Bearing in mind what you say I have tried eliminating each of these but the result is always the same. The TB files always load twice. I have tried loading the TB files first and the others afterwards but this has not worked either. For the moment I don't know what else to try. The other depressing thing is that the file is so full I regularly have trouble exporting it to DHTML. Surprisingly re-starting the computer usually allows me to continue but I can't see any TB files running in the Task Manager.
On the positive side I have come a long way very fast on another aspect of the program. My original translation database was in XLS format. I converted this to CSV via an online app and then from CSV to XML. With very little coding I have quite an impressive result. The database has 700 lines and 5 columns corresponding to 5 different languages. The translations arrive in a split second! Of course this probably means yet more loading via pgGotoURL unless I can combine it with another HTML. Anyway here's the result: http://www.mediacours.com/gettext It cheered me up a lot.
Thanks for your help. I did what you suggested but the problem is still there. I am loading 3 HTML docs and 2 TB DHTMLs. Bearing in mind what you say I have tried eliminating each of these but the result is always the same. The TB files always load twice. I have tried loading the TB files first and the others afterwards but this has not worked either. For the moment I don't know what else to try. The other depressing thing is that the file is so full I regularly have trouble exporting it to DHTML. Surprisingly re-starting the computer usually allows me to continue but I can't see any TB files running in the Task Manager.
On the positive side I have come a long way very fast on another aspect of the program. My original translation database was in XLS format. I converted this to CSV via an online app and then from CSV to XML. With very little coding I have quite an impressive result. The database has 700 lines and 5 columns corresponding to 5 different languages. The translations arrive in a split second! Of course this probably means yet more loading via pgGotoURL unless I can combine it with another HTML. Anyway here's the result: http://www.mediacours.com/gettext It cheered me up a lot.